
My Recent Research Projects
HealthyPlan.City: A Web Tool to Support Urban Environmental Equity and Public Health in Canadian Communities
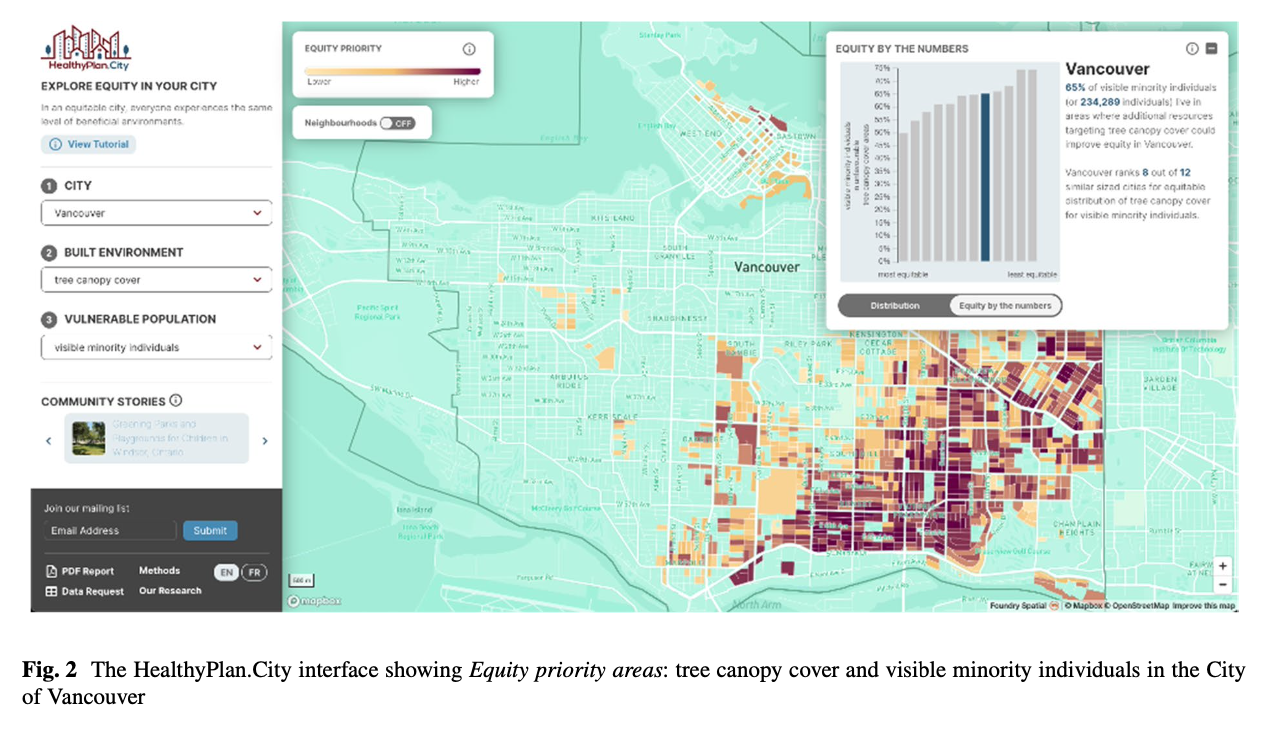
Urban environmental factors such as air quality, heat islands, and access to greenspaces and community amenities impact public health. Some vulnerable populations such as low-income groups, children, older adults, new immigrants, and visible minorities live in areas with fewer beneficial conditions, and therefore, face greater health risks. Planning and advocating for equitable healthy urban environments requires systematic analysis of reliable spatial data to identify where vulnerable populations intersect with positive or negative urban/environmental characteristics. To facilitate this effort in Canada, we developed HealthyPlan.City (https://healthyplan.city/), a freely available web mapping platform for users to visualize the spatial patterns of built environment indicators, vulnerable populations, and environmental inequity within over 125 Canadian cities. This tool helps users identify areas within Canadian cities where relatively higher proportions of vulnerable populations experience lower than average levels of beneficial environmental conditions, which we refer to as Equity priority areas. Using nationally standardized environmental data from satellite imagery and other large geospatial databases and demographic data from the Canadian Census, HealthyPlan.City provides a block-by-block snapshot of environmental inequities in Canadian cities. The tool aims to support urban planners, public health professionals, policy makers, and community organizers to identify neighborhoods where targeted investments and improvements to the local environment would simultaneously help communities address environmental inequities, promote public health, and adapt to climate change. In this paper, we report on the key considerations that informed our approach to developing this tool and describe the current web-based application.
Predicting Diabetes in Canadian Adults Using Machine Learning
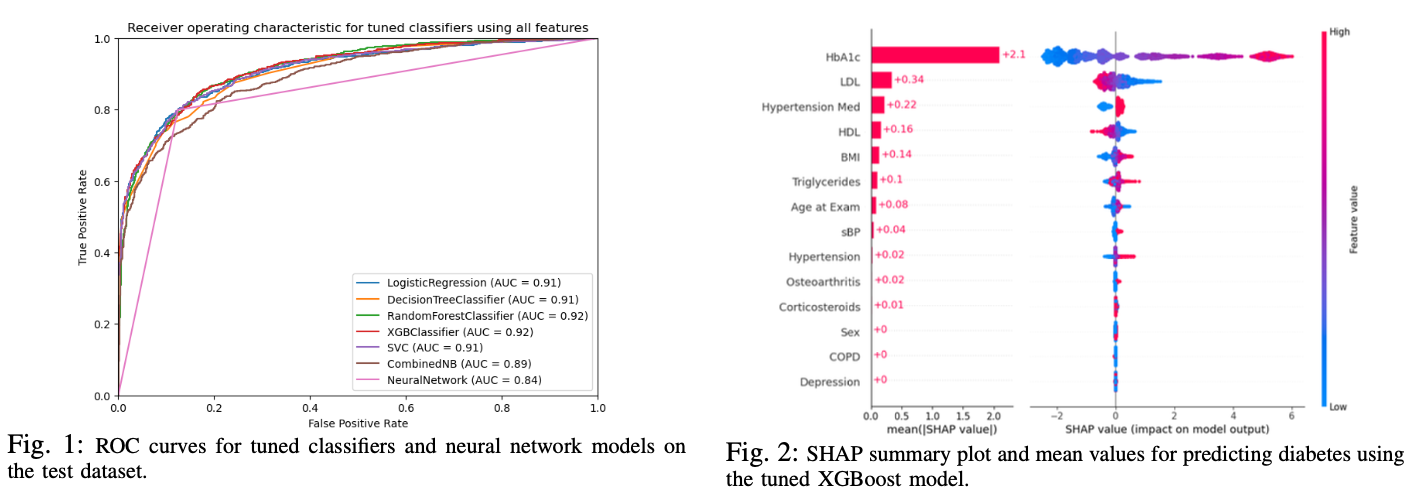
Rising diabetes rates have led to increased healthcare costs and health complications. An estimated half of diabetes cases remain undiagnosed. Early and accurate diagnosis is crucial to mitigate disease progression and associated risks. This study addresses the challenge of predicting diabetes prevalence in Canadian adults by employing machine learning (ML) techniques to primary care data. We leveraged the Canadian Primary Care Sentinel Surveillance Network (CPCSSN), Canada’s premier multi-disease electronic medical record surveillance system, and developed and tuned seven ML classification models to predict the likelihood of diabetes. The models were tested and validated, focusing on clinical patient characteristics influential in predicting diabetes. We found XGBoost performed best out of all the models, with an AUC of 92%. The most important features contributing to model prediction were HbA1c, LDL, and hypertension medication. Our research aims to aid healthcare professionals in early diagnosis and to identify key characteristics for targeted interventions. This study contributes to an understanding of how ML can enhance public health planning and reduce healthcare system burdens.
Predicting Donor Selection and Multi-Organ Transplantation within Organ Procurement Organizations Using Machine Learning
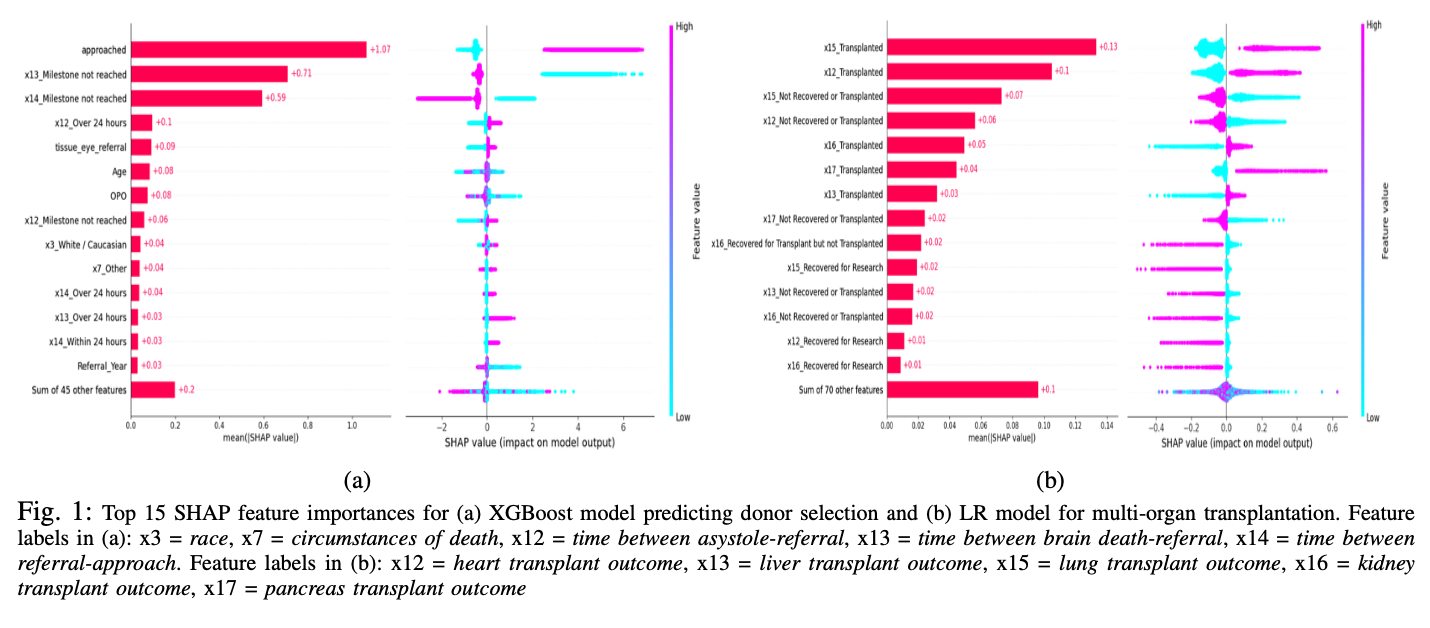
Organ procurement organizations (OPOs) play a crucial role in the field of organ transplantation, serving as key intermediaries in the process of organ donation. However, despite their vital function, there exists a pressing issue of transparency within the organ allocation process. This opacity not only impedes the overall effectiveness of OPOs but also raises ethical and societal concerns regarding organ distribution. This study utilizes the recently published ORCHID dataset, containing 133,101 records of organ donor referrals, to understand organ procurement and donor selection strategies in OPOs using machine learning (ML). We developed seven ML classification models to predict donor selection and the likelihood of at least four organs being suitable for transplantation, in line with established definitions of multi-organ transplantation. The models demonstrated variable recall values for donor selection, ranging between 0.62 and 0.80, while achieving consistently high performance across other evaluation metrics, notably with AUC values exceeding 0.95. Particularly in the context of multi-organ transplant predictions, the models exhibited remarkable effectiveness, with recall values spanning from 0.88 to 0.98 and AUC metrics consistently above 0.97. Administrative milestones and particular organ transplants were identified as key determinants in the organ allocation process. This study’s findings suggest significant opportunities to improve organ allocation strategies by focusing on the optimization of administrative practices, highlighting their substantial impact on transplantation success rates.
Predicting Depression Among Canadians At-Risk or Living with Diabetes Using Machine Learning
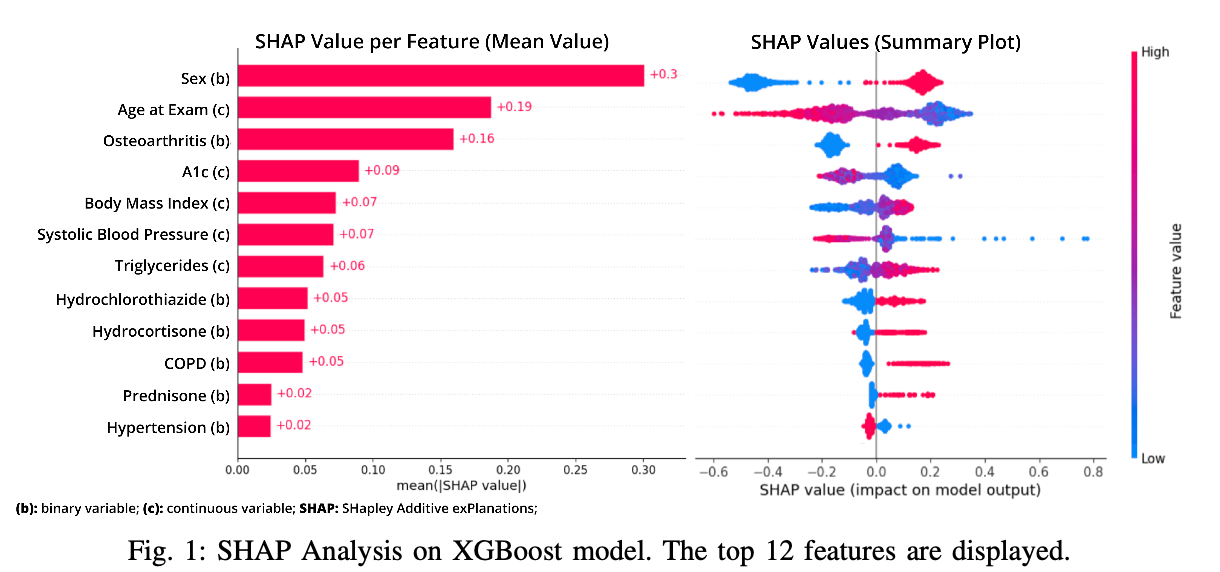
Depression is disproportionately prevalent among individuals with diabetes compared to the general populace, underscoring the critical need for predictive mechanisms that can facilitate timely interventions and support. This study explores the use of machine learning to forecast depression in those at risk or diagnosed with diabetes, leveraging the extensive primary care data from the Canadian Primary Care Sentinel Surveillance Network. Six machine learning models including Logistic Regression, Random Forest, AdaBoost, XGBoost, Naive Bayes, and Artificial Neural Networks were trained and evaluated on their ability to predict depression. XGBoost emerged as the most effective model with an AUC of 0.70 on the test data. Sex, age, osteoarthritis, A1c levels, and body mass index emerged as the key contributors to the bestperforming model’s predictive ability. While the study navigated through the constraints of limited demographic information and potential label bias, it lays a foundational premise for subsequent longitudinal studies aimed at refining depression prediction within this specific clinical cohort.
Predicting Time to Diabetes Diagnosis Using Random Survival Forests
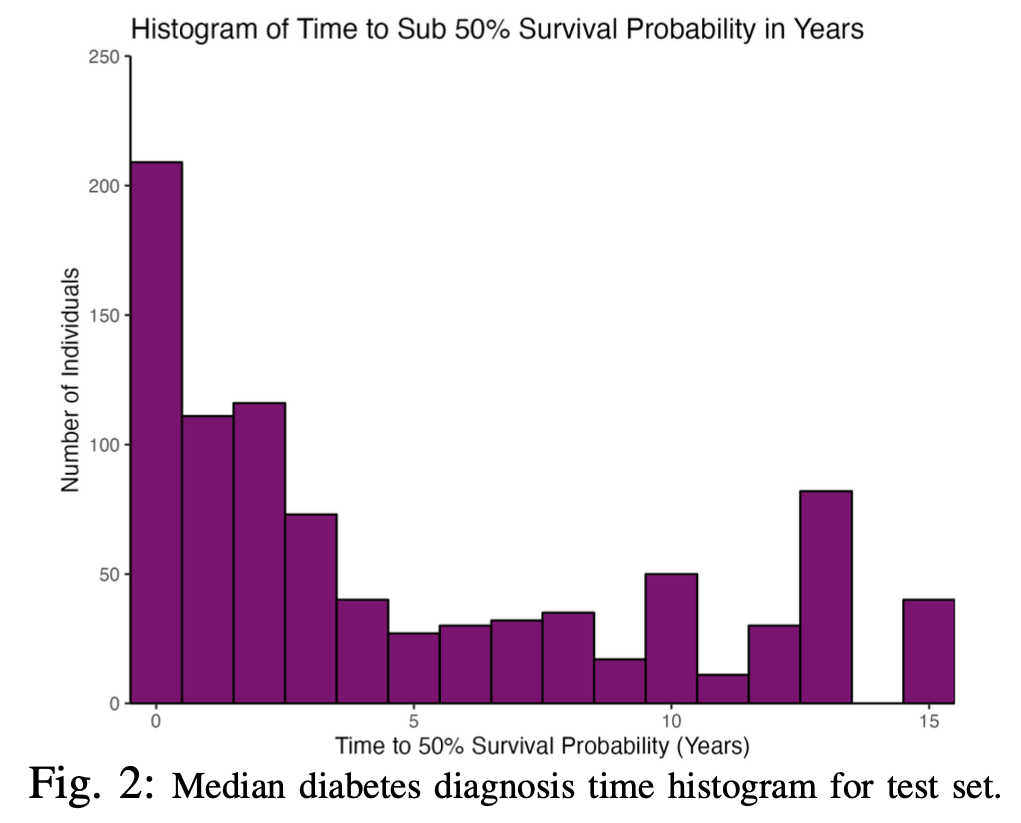
Type 2 Diabetes Mellitus (T2DM) is a chronic metabolic disorder with increasing population incidence. However, T2DM takes years to develop, allowing onset prediction and prevention to be a clinically effective treatment strategy. In this study we propose and assess a novel approach to diabetes prediction which integrates a specialized extension of the random forest algorithm known as random survival forest (RSF). Rather than predicting a binary outcome, this machine learning model incorporates survival analysis methodology to predict the time until a patient will receive a diabetes diagnosis if their current lifestyle is maintained. We trained a baseline model on 7,704 electronic medical records from the Canadian Primary Care Sentinel Surveillance Network (CPCSSN) with 14 biomarker and comorbidity features across different measurement dates. Although tuning parameters were purposefully chosen for quick training rather than for predictive performance, our model exceeded expectations with a concordance index of 0.84. Thus, RSF models have been shown to produce accurate timelines of diabetes onset trajectory, providing patients with quantifiable and relatable risks that are easy to understand. The results of our study have substantial implications for advancing machine learning in clinical decision support and patient outcome predictions, emphasizing the role of innovative models in improving predictive accuracy.
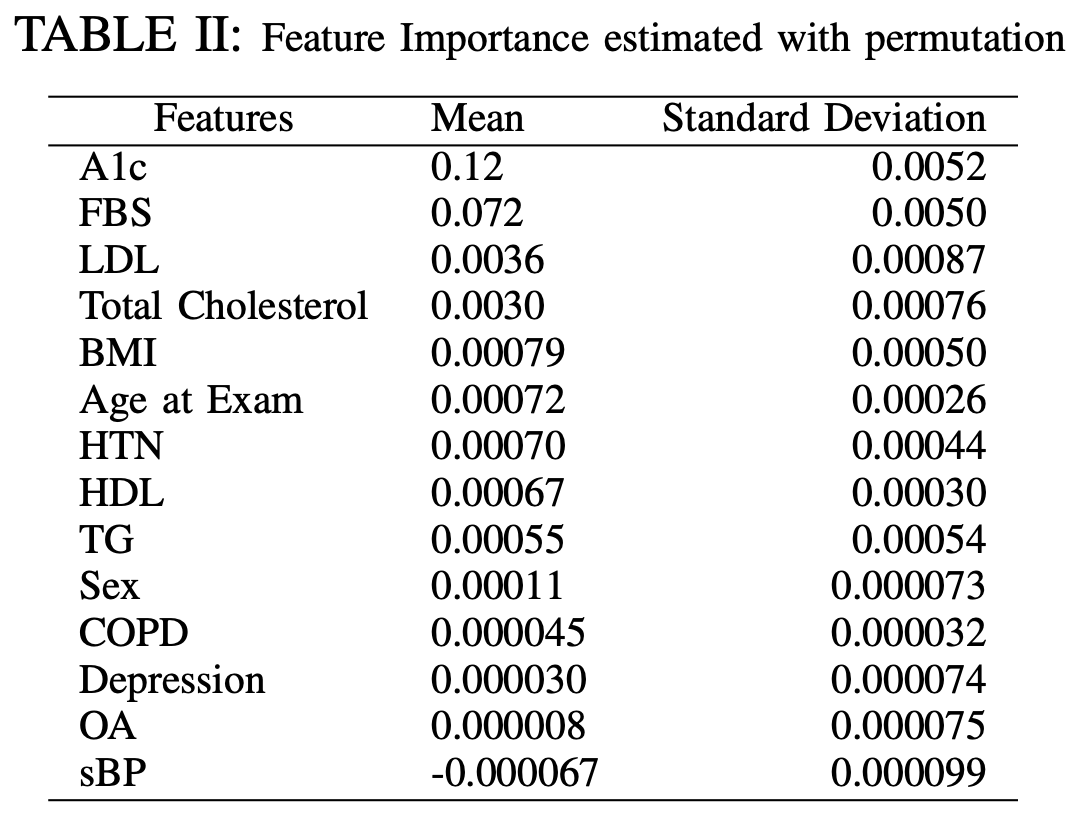
Identifying Prediabetes in Canadian Populations Using Machine Learning
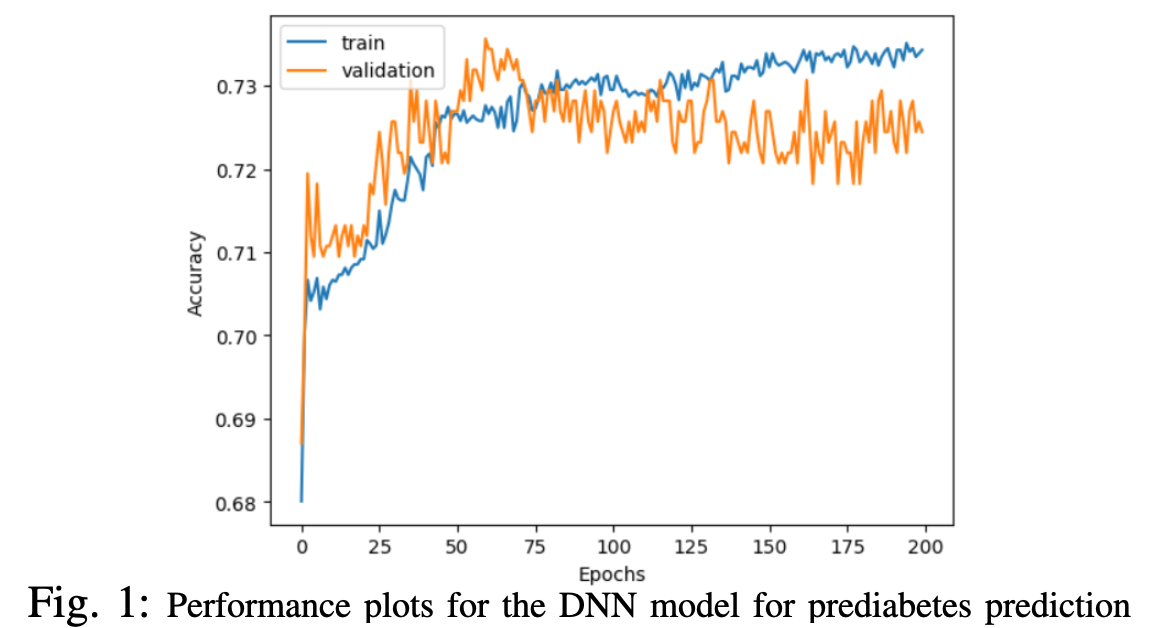
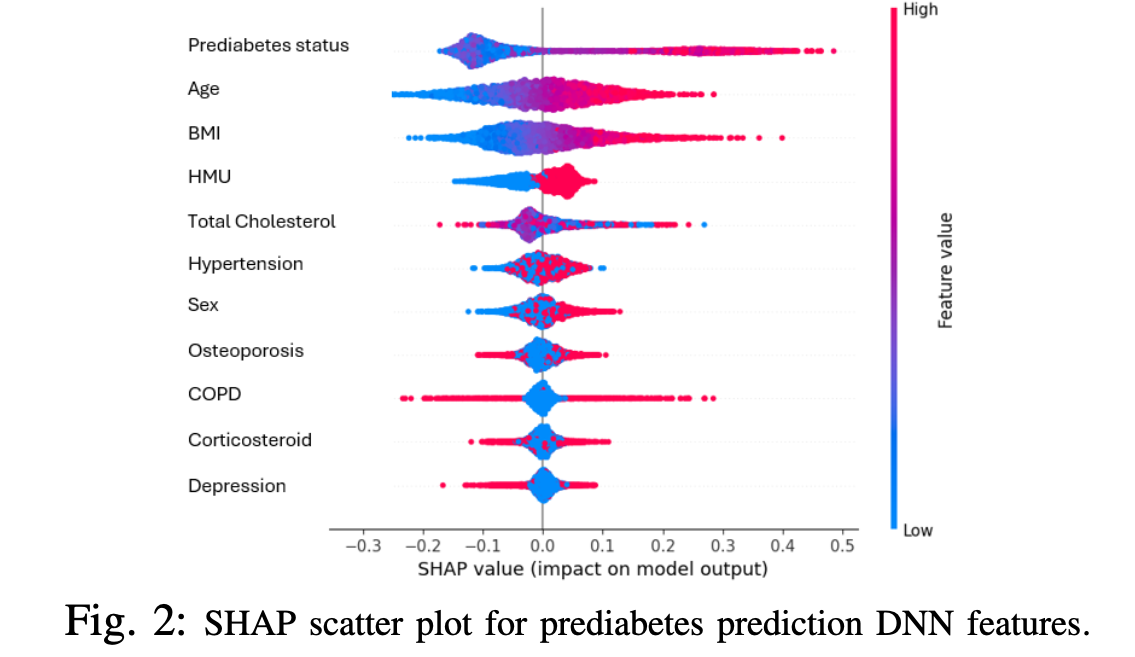
— Prediabetes is a critical health condition characterized by elevated blood glucose levels that fall below the threshold for Type 2 diabetes (T2D) diagnosis. Accurate identification of prediabetes is essential to forestall the progression to T2D among at-risk individuals. This study aims to pinpoint the most effective machine learning (ML) model for prediabetes prediction and to elucidate the key biological variables critical for distinguishing individuals with prediabetes. Utilizing data from the Canadian Primary Care Sentinel Surveillance Network (CPCSSN), our analysis included 6,414 participants identified as either nondiabetic or prediabetic. A rigorous selection process led to the identification of ten variables for the study, informed by literature review, data completeness, and the evaluation of collinearity. Our comparative analysis of seven ML models revealed that the Deep Neural Network (DNN), enhanced with early stop regularization, outshined others by achieving a recall rate of 60%. This model’s performance underscores its potential in effectively identifying prediabetic individuals, showcasing the strategic integration of ML in healthcare. While the model reflects a significant advancement in prediabetes prediction, it also opens avenues for further research to refine prediction accuracy, possibly by integrating novel biological markers or exploring alternative modeling techniques. The results of our work represent a pivotal step forward in the early detection of prediabetes, contributing significantly to preventive healthcare measures and the broader fight against the global epidemic of Type 2 diabetes.
Perimeter Control Using Deep Reinforcement Learning: A Model-free Approach towards Homogeneous Flow Rate Optimization
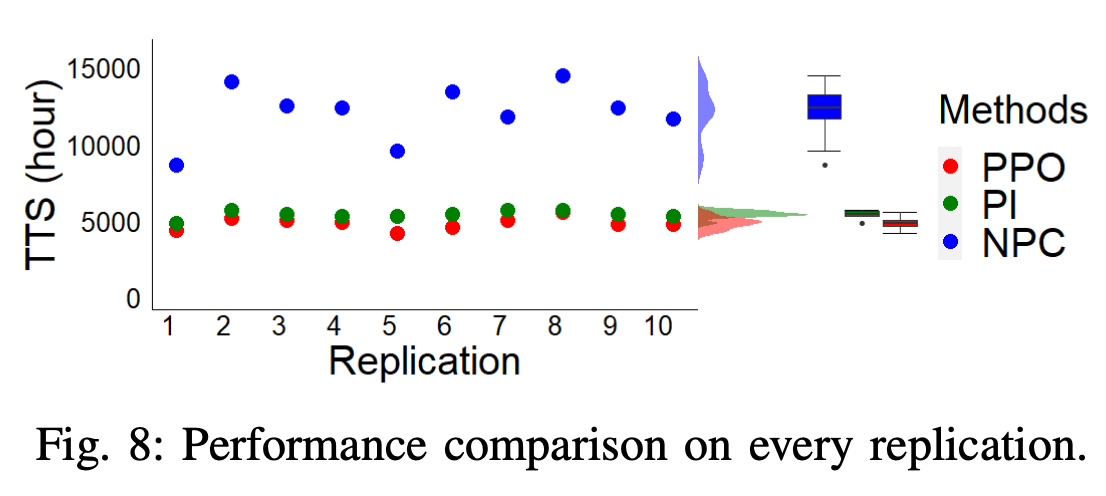
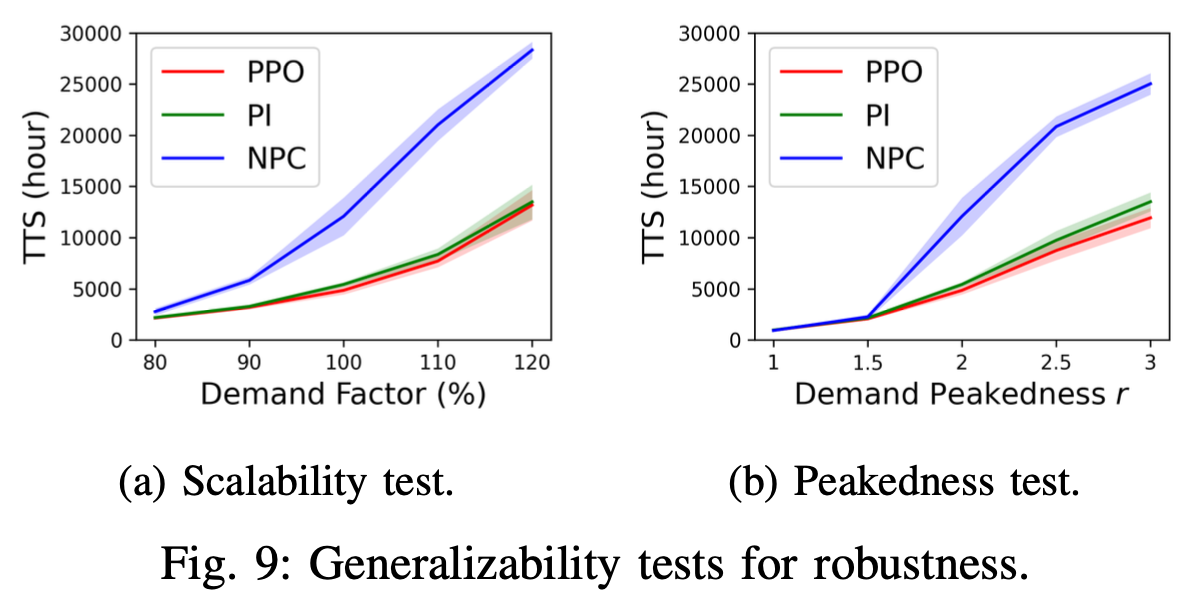
Perimeter control maintains high traffic efficiency within protected regions by controlling transfer flows among regions to ensure that their traffic densities are below critical values. Existing approaches can be categorized as either model- based or model-free, depending on whether they rely on network transmission models (NTMs) and macroscopic funda- mental diagrams (MFDs). Although model-based approaches are more data efficient and have performance guarantees, they are inherently prone to model bias and inaccuracy. For example, NTMs often become imprecise for a large number of protected regions, and MFDs can exhibit scatter and hysteresis that are not captured in existing model-based works. Moreover, no existing studies have employed reinforcement learning for homogeneous flow rate optimization in microscopic simula- tion, where spatial characteristics, vehicle-level information, and metering realizations — often overlooked in macroscopic simulations — are taken into account. To circumvent issues of model-based approaches and macroscopic simulation, we explore a model-free deep reinforcement learning approach that optimizes the flow rate homogeneously at the perimeter at the microscopic level. Additionally, we investigate different arrangements of the agent’s state space to assess the importance of different state variables. Results demonstrate that the model- free reinforcement learning approach without any knowledge of NTMs or MFDs can compete and match the performance of a model-based approach, and exhibits enhanced generalizability and scalability.
Unlocking the power of EHRs: harnessing unstructured data for machine learning-based outcome predictions
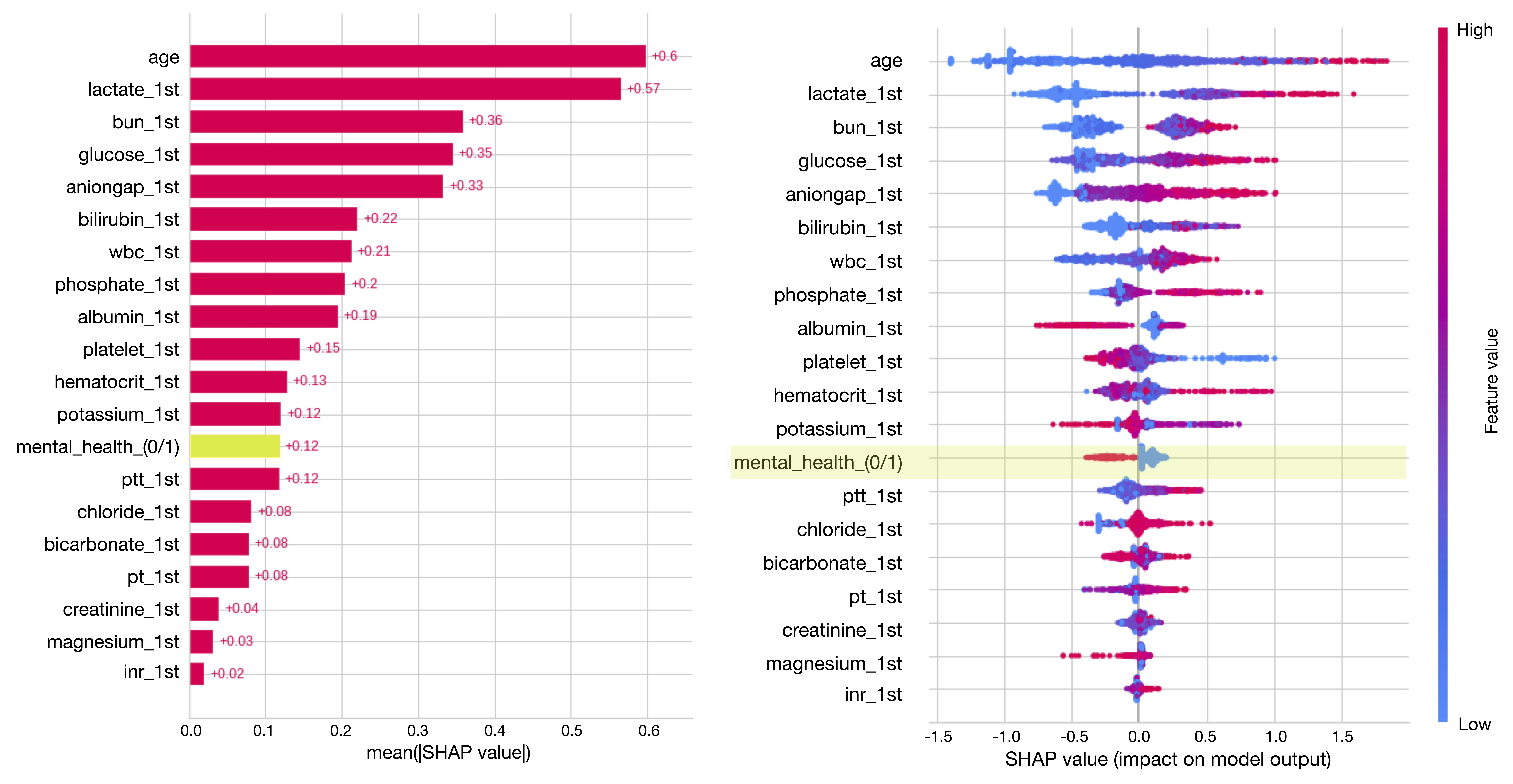
The integration of Electronic Health Records (EHRs) with Machine Learning (ML) models has become imperative in examining patient outcomes due to the vast amounts of clinical data they provide. However, critical information regarding social and behavioral factors that affect health, such as social isolation, stress, and mental health complexities, is often recorded in unstructured clinical notes, hindering its accessibility. This has resulted in an over-reliance on clinical data in current EHR-based research, potentially leading to disparities in health outcomes. This study aims to evaluate the impact of incorporating patient-specific context from unstructured EHR data on the accuracy and stability of ML algorithms for predicting mortality, using the MIMIC III database. Results from the study confirmed the significance of incorporating patient-specific information into prediction models, leading to a notable improvement in the discriminatory power and robustness of the ML algorithms. Furthermore, the findings underline the importance of considering non-clinical factors related to a patient’s daily life, in addition to clinical factors, when making predictions about patient outcomes. The advent of advanced generative models, such as GPT-4, presents new opportunities for effectively extracting social and behavioral factors from unstructured clinical notes, further enhancing the accuracy and stability of ML algorithms in predicting patient outcomes. The results of our study have significant ramifications for improving ML in clinical decision support and patient outcome predictions, specifically highlighting the potential role of generative models like GPT-4 in advancing ML-based outcome predictions.
Real-time Decentralized Traffic Signal Control for Congested Urban Networks Considering Queue Spillbacks
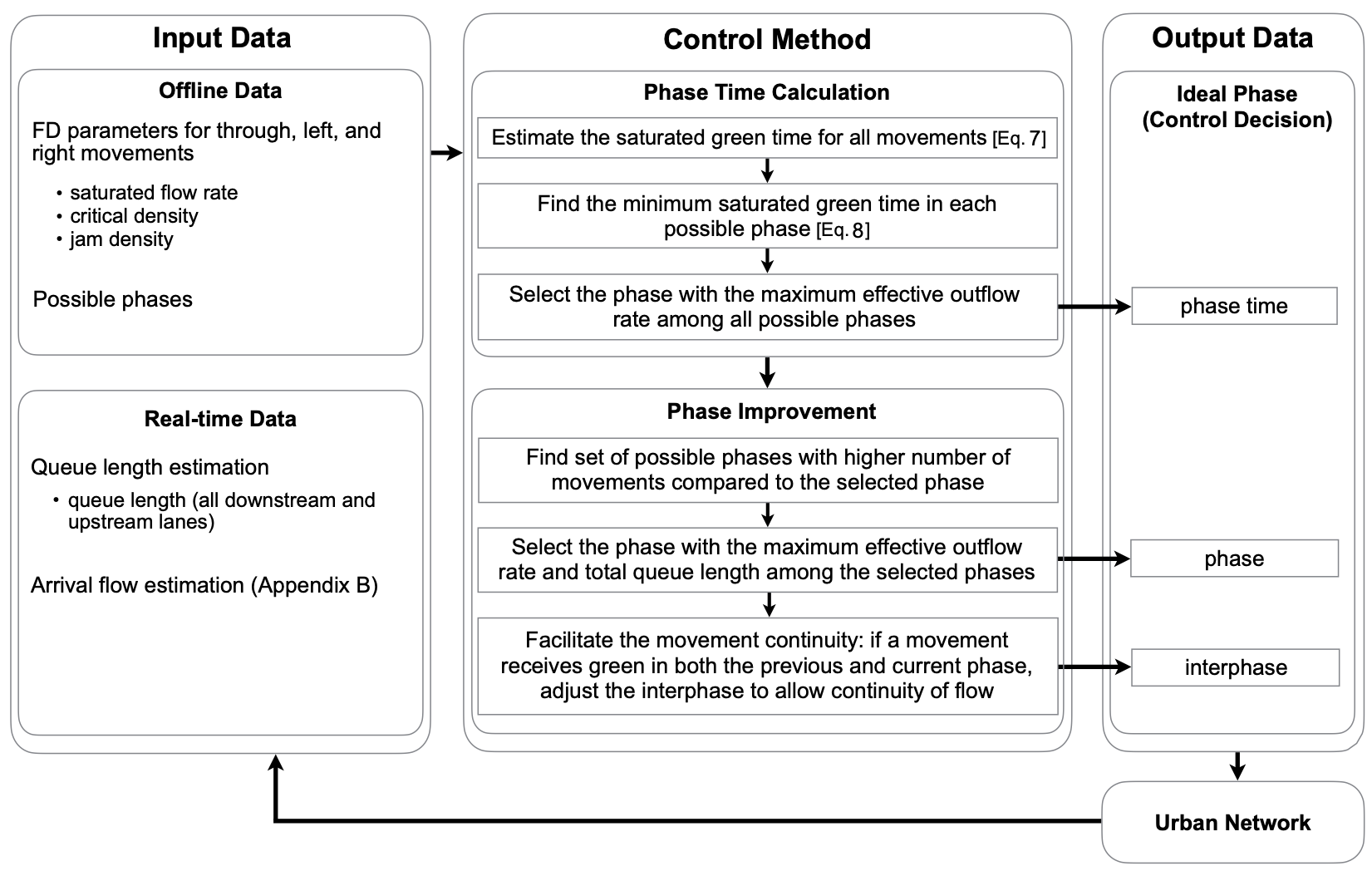
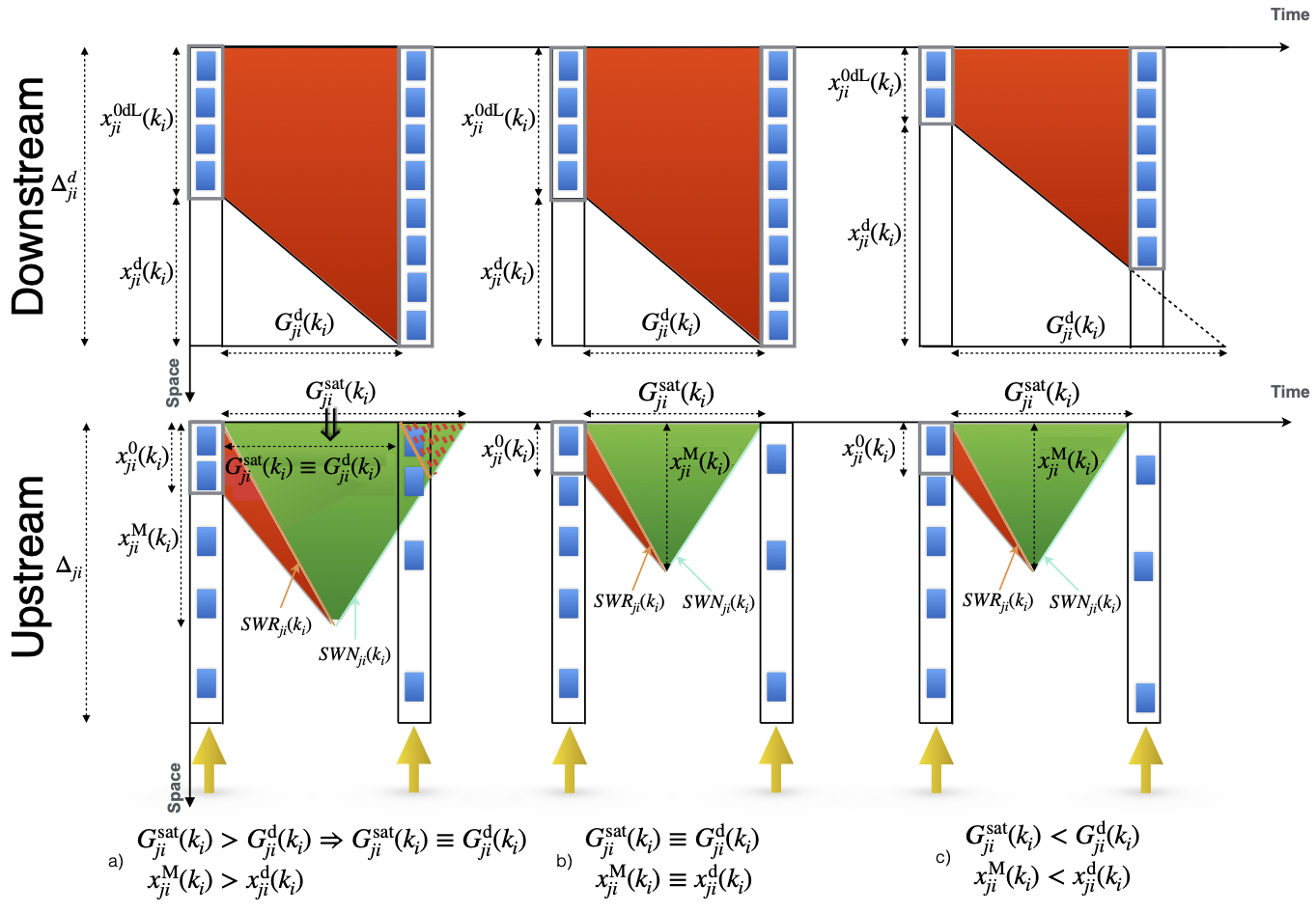
This research proposes a decentralized network-level traffic signal control method addressing the effects of queue spillbacks. The method is traffic-responsive, does not require data communication between intersections’ controllers, uses lane-based queue measurements, and is acyclic. Each traffic controller operating at an intersection aims at maximizing the effective outflow rate locally and independently with the goal of maximizing global throughput of the entire network. At each intersection, the signal control method estimates and adopts the maximum possible phase time in which all active movements discharge at their full capacity. This is modeled using a shockwave based queue length estimation model while capturing the spillback at the downstream links. The method demands real-time data including, the queue lengths, the arrival flows, and the downstream queue lengths in all the lanes at the control decision times. The proposed method results in a feasible solution in all conditions in the entire network with any scale within a short amount of time. A stability concept for the traffic network is defined, and asymptotic stability of the controlled traffic network are verified. Moreover, a sufficient condition for the optimality of the proposed control algorithm for maximizing the instantaneous total throughput of the network intersections is demonstrated. Numerical results show that the proposed method outperforms benchmark methods in both isolated intersection and network configurations.
Bi-modal Perimeter Control: A Hybrid Control Approach Integrating Proportional Integral Controller and Deep Reinforcement Learning
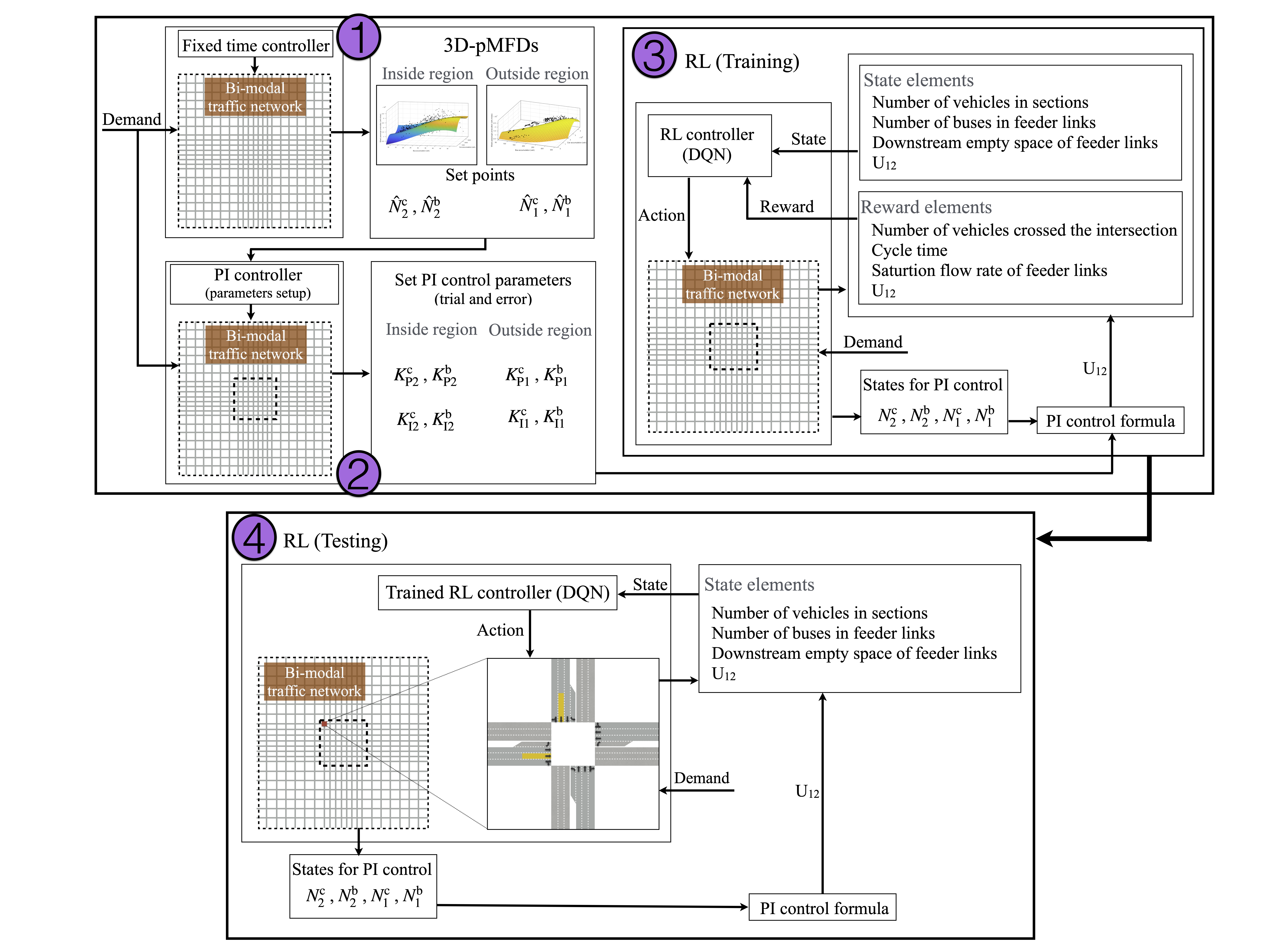
This research proposes a hierarchical perimeter control method in a large-scale urban network consisting of car and public transit modes. We design a hierarchical proportional-integral (PI) control based deep reinforcement learning (deep RL) method to control each intersection on the perimeter independently. The PI control in the high-level of our controller is designed to reduce the state space and at the same time reflect the perimeter control input in the reward function of the deep RL method. The PI control is established on a passenger-based MFD of the network, called 3D-pMFD, which provides the set points, i.e. optimal points, of both inside and outside regions. Using the multivariable PI controller’s parameters based on the obtained set points, a reinforcement learning method is applied in the low-level controller to time each traffic signal on the perimeter without receiving any data from other traffic signals in the network, except vehicles accumulations in the network. The results show a significant improvement of the proposed method compared to the fixed time and PI control methods in terms of total passenger delay.
Digital Public Health Surveillance (DPHS)
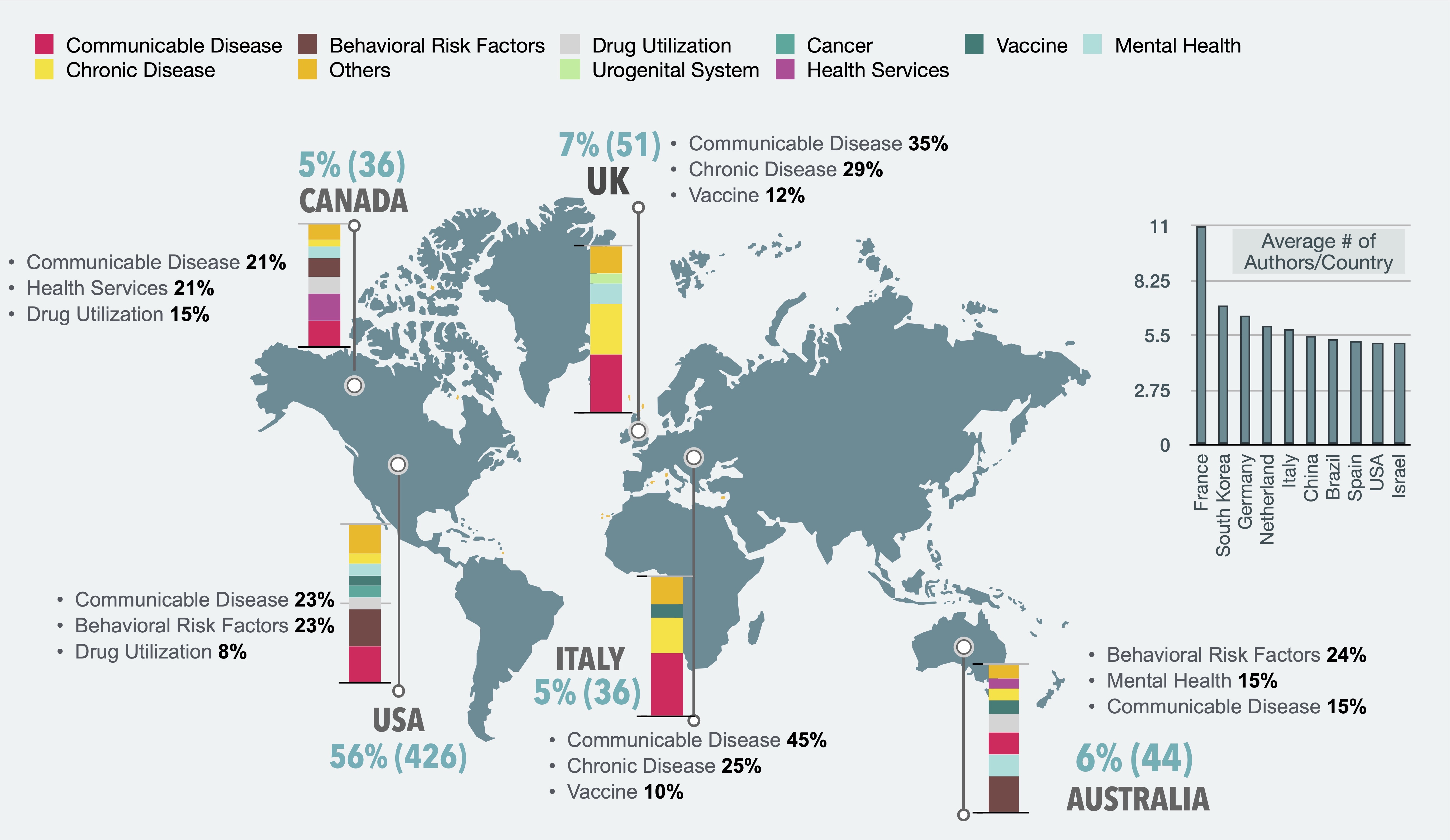
In this research, I utilized natural language processing, qualitative analysis, and visualization techniques to consolidate and characterize the existing research on DPHS and identify areas for further research. In this research, we conducted a comprehensive systematic scoping review of 755 articles on DPHS published from 2005 to January 2020. The studies included in this review were from 54 countries and utilized 26 digital platforms to study 208 sub-categories of 49 categories associated with 16 public health surveillance (PHS) themes. In addition to discussing the potentials of using Internet-based data as an affordable and instantaneous resource for DPHS, this research also highlights the paucity of longitudinal studies and the methodological and inherent practical limitations underpinning the successful implementation of a DPHS system. Little work studied Internet users’ demographics when developing DPHS systems, and 39% (291) of studies did not stratify their results by geographic region. A clear methodology by which the results of DPHS can be linked to public health action has yet to be established, as only six (0.8%) studies deployed their system into a PHS context. I also developed an interactive visual dashboard to provide insights into the findings with a multidimensional and more granular conceptual structure that is difficult to articulate in text alone.
The Efficacy of Using Social Media Data for Designing Traffic Management Systems
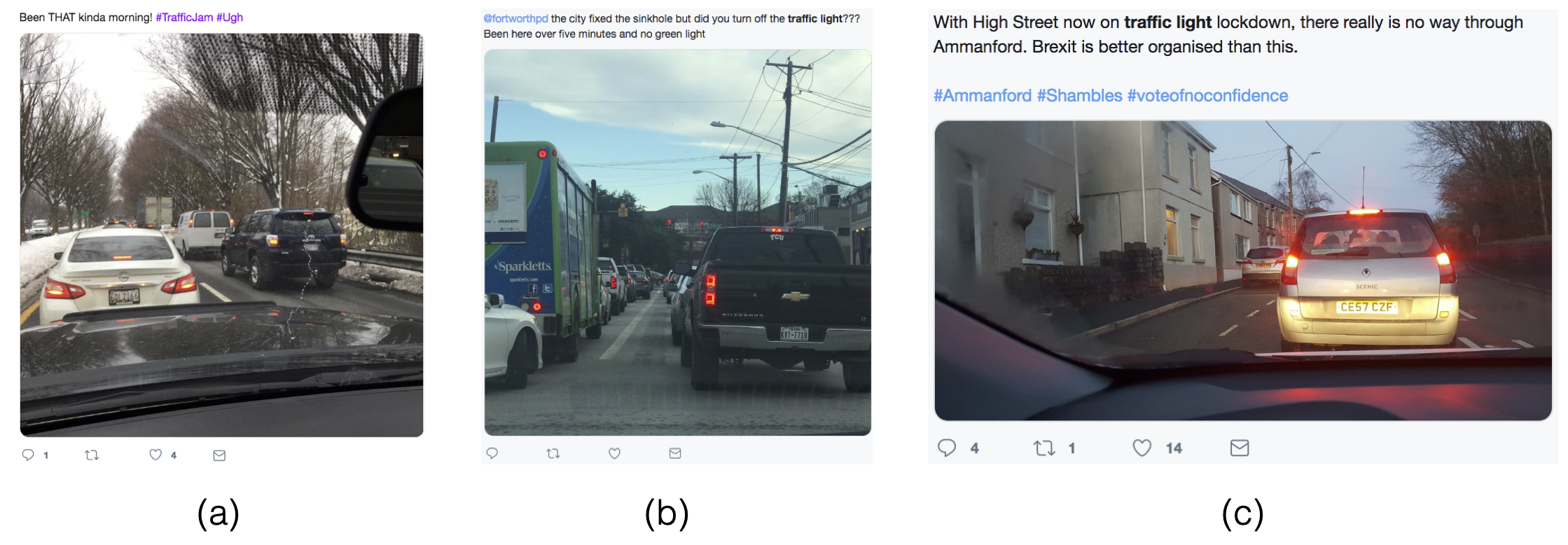
It has long been acknowledged in the context of developing dynamic and reactive systems that users’ input during different stages of the development process helps to quickly and incrementally adapt to changes in the system’s context and users’ needs. Given the data- and communication-intensive nature of developing transportation management systems, utilizing social media data provides a new route for a dynamic collection of needs and experiences in a timely and direct fashion. In this research, we will explore how and to what extent social media data can support urban traffic management systems. To this end, we have conducted a mixed-method study including both manual qualitative analysis, and automatic information extraction using weighted finite-state transducers (WFST), natural language processing (NLP), and deep neural networks (DNN) on Twitter data. We utilize Canadian traffic information from twitter to look for issues and relevant information that may assist authorities and software development teams in making decisions when designing and developing traffic management systems by leveraging lay people’s input. Data triangulation will also be used to help compare our results against other data sources such as Google Trends and scientific material. We found that the self-reported traffic information with lay users on Twitter can be a valuable source to characterize traffic management systems. Moreover, we found that although theory-based publications in the context of traffic management systems can help with traffic estimation, control, and prediction, they are insufficient to characterize the context-sensitive aspects of these systems.
Reinforcement Learning in Urban Network Traffic Signal Control: A Systematic Literature Review
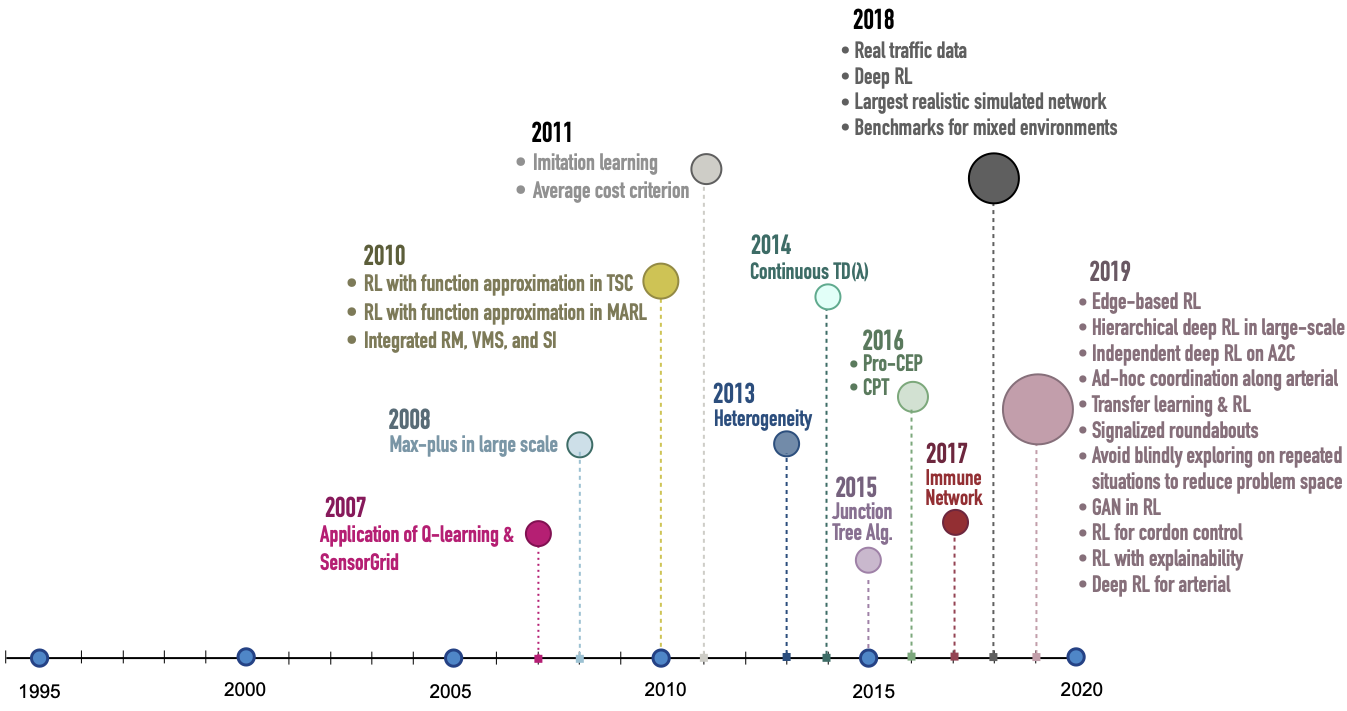
Improvement of traffic signal control (TSC) efficiency has been found to lead to improved urban transportation and enhanced quality of life. Recently, the use of reinforcement learning (RL) in various areas of TSC has gained significant traction; thus, we conducted a systematic literature review as a systematic, comprehensive, and reproducible review to dissect all the existing research that applied RL in the network-level TSC (NTSC) domain. The review only targeted the network-level articles that tested the proposed methods in networks with two or more intersections. This review covers 160 peer-reviewed articles from 30 countries published from 1994 to March 2020. The goal of this study is to provide the research community with statistical and conceptual knowledge, summarize existence evidence, characterize RL applications in NTSC domains, explore all applied methods and major first events in the defined scope, and identify areas for further research based on the explored research problems in current research. We analysed the extracted data from the included articles in the following seven categories: (1) publication and authors’ data, (2) method identification and analysis, (3) environment attributes and traffic simulation, (4) application domains of RL in NTSC, (5) major first events in RL-NTSC and authors’ key statements, (6) code availability, and (7) evaluation. This research provides a comprehensive view of the past 26 years of research on applying RL to NTSC. It reveals the role of advancing deep learning methods in the revival of the research area, the rise of using non-commercial microscopic traffic simulators, a lack of interaction between traffic and transportation engineering practitioners and researchers, and a lack of proposal and creation of testbeds which can likely bring different communities together around common goals.